Many consumer laptops have integrated Intel GPUs like the Intel Arc graphics processor. In contrast to Nvidia GPUs, it’s still quite hard to use Intel GPUs for LLM training and inference or deep learning in general, at least from my experience on Linux. I’ve written down the necessary steps here for setting up GPU acceleration with an Intel GPU on Ubuntu 24.04 using a quantized Llama 3.2 model via llama.cpp Python bindings as an practical example. As a positive side effect, your system will also be set up to support GPU processing via OpenCL, which can improve the performance of many applications such as the open source photo editing tool Darktable.
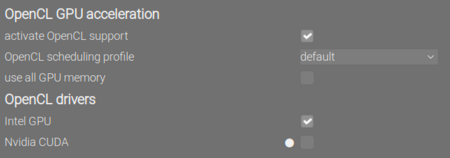
To use an Intel-based GPU for processing, the company provides the OneAPI toolkit. At first, you should check that your system meets the hardware requirements. The next step is to install the GPU driver. After a reboot, run clinfo | grep "Device Name" which should list your GPU. You have now installed the GPU driver and OpenCL support. NB: If you’re using software that supports OpenCL, you can now activate OpenCL support in it, which should speed up compute intensive tasks. An example is Darktable that under “Preferences > Processing” should now allow to activate OpenCL GPU acceleration:
The next task is to install the Intel oneAPI Base Toolkit. It’s enough to add the APT sources and then install the toolkit, i.e. following the first two steps and ignoring the rest. You must however also install some additional runtime libraries, if you later want to use llama.cpp: sudo apt install intel-oneapi-runtime-libs. A reboot can’t hurt and after that, open a terminal and run source /opt/intel/oneapi/setvars.sh. This is a very central command – whenever you need to run software the wants to use GPU acceleration via the OneAPI toolkit, you will first need to run this command. You may consider to edit your .bashrc and add the following line, which will cause to set up OneAPI everytime you open a terminal:
source /opt/intel/oneapi/setvars.sh > /dev/null 2>&1
I personally didn’t add this to my .bashrc, since I was not sure how it meddles with my system (and it also slows down terminal startup), so I only run this script whenever I need GPU acceleration. Anyway, after running this OneAPI set up script, you should run sycl-ls (in the same terminal session!) and again check that your GPU is listed there.
Next, we install the llama.cpp Python bindings. First, make sure that you’ve run the OneAPI setup script (setvars.sh) as shown above. Using the same terminal session, install the llama.cpp bindings via your preferred Python package manager:
When using pip, create and activate a Python virtual environment (“venv”) and then run
CMAKE_ARGS="-DGGML_SYCL=on -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx" \
pip install llama-cpp-python
pip install huggingface_hub
Alternatively, when using uv, initialize a project with uv then change into the project’s directory and run
CMAKE_ARGS="-DGGML_SYCL=on -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx" \
uv add llama-cpp-python
uv add huggingface_hub
To check that it works, run a Python console in the same terminal session (python or uv run python) with the following script:
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="hugging-quants/Llama-3.2-1B-Instruct-Q8_0-GGUF",
filename="*q8_0.gguf",
)
output = llm.create_chat_completion(
messages = [
{
"role": "user",
"content": "What is the capital of France?"
}
]
)
print(output)
This should create an output dict that contains a message stating something like “… the walrus operator := was introduced with Python 3.8 …”, etc.
On my hardware, running this script without GPU acceleration (i.e. solely on the CPU), an output would not be created even after minutes of processing (my patience ended after ten minutes). However, using GPU acceleration, I get a result after about 6 seconds. Note that the script doesn’t employ streamed inference, hence it will only display something when the whole output was generated.
Now when you do software development and want to run your scripts from inside your IDE, this may fail with an error like that:
terminate called after throwing an instance of 'sycl::_V1::exception'
what(): No device of requested type available.
The problem is that the Intel OneAPI GPU acceleration is not set up automatically from your IDE, i.e. the setvars.sh script is not run prior to script execution and hence the environment variables necessary for GPU acceleration are not set. I’m using PyCharm and I could set it up to run that OneAPI setup script before executing my Python script, but the environment variables are not passed on to the Python script. My solution was then to set the environment variables manually like this:
- Open a terminal and run
source /opt/intel/oneapi/setvars.sh. - In the same terminal, run
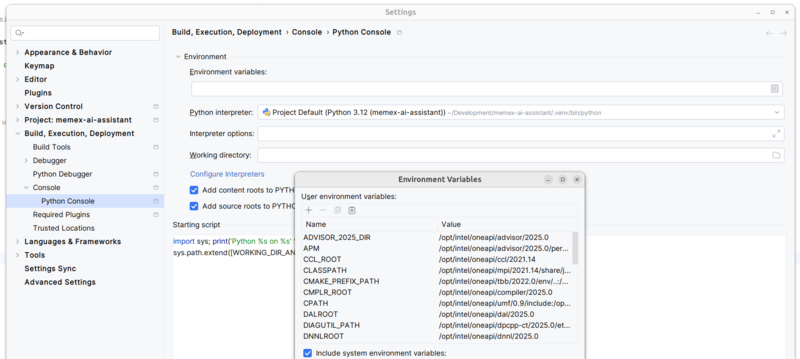
printenv | grep -i inteland copy the output – this will capture all Intel-related environment variables. - Open your project in PyCharm, and go to “Settings > Build, Execution, Deployment > Console > Python Console > Environment Variables” (see first screenshot below), then:
- Click on icon on the right side, then click on “Paste”. All environment variables should be listed in upper table.
- Reload the Python console.
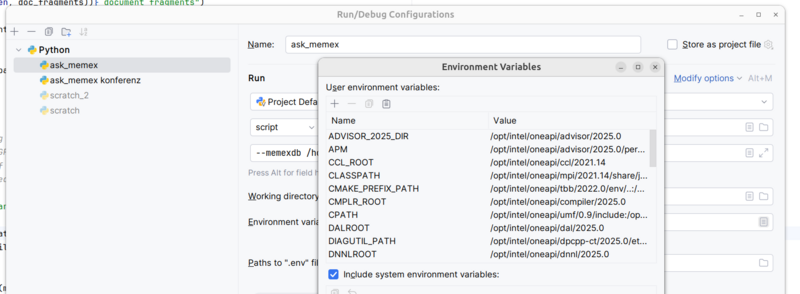
- For each Run configuration, paste the output from step 2 to the “Environment variables” table similar to step 3 (see second screenshot below).
Now you can start developing software with GPU acceleration directly on your Intel based laptop. On my machine (Intel Core Ultra 7), I could even get the non-quantized Llama 3.2 models running (though quite slow).